式を使った行検索
モダン ABAP では、式指向の簡易なコードで内部テーブルの行データを検索できる。
行番号を指定した検索
行番号を指定して検索する場合の基本形は以下の通り。
内部テーブル名[ 行番号 ]
内部テーブル名の後に、検索する行番号を [ ] で囲んで指定する。[ の後と ] の前には半角スペースを挟む。検索した行データは、= を使って左辺に代入される。
以下のコードは、従来のコーディングで、内部テーブル profiles の 1 行目のデータを検索し、検索したデータを構造 profile に代入している。
DATA: profiles TYPE TABLE OF zs_profile,
profile TYPE zs_profile.
....
READ TABLE profiles INTO profile INDEX 1.このコードを式指向で書き換えると、以下のようになる。
DATA profiles TYPE zt_profile.
....
DATA(profile) = profiles[ 1 ].条件を指定した検索
内部テーブルの行データを条件検索する場合の基本形は以下の通り。
内部テーブル名[ 変数名 = 検索条件の値 ... ]
内部テーブル名の後に、検索条件を [ ] で囲んで指定する。[ の後と ] の前には半角スペースを挟む。なお、検索条件の記述方法は、READ TABLE の WITH KEY 句と変わらない。
以下のコードは、従来のコーディングで、内部テーブル profiles から行データを条件検索している。
DATA: profiles TYPE TABLE OF zs_profile,
profile TYPE zs_profile.
....
PARAMETERS: height TYPE ze_height OBLIGATORY,
uninum TYPE ze_uninumber OBLIGATORY.
....
READ TABLE profiles INTO profile
WITH KEY height = height uninumber = uninum.これをモダン ABAP で書き換えると、以下のようになる。
DATA(profile) = profiles[ height = height uninumber = uninum ].式指向のコードで内部テーブル profiles を検索し、検索結果をインライン宣言した構造 profile に代入している。
インライン宣言の例外対応
前述のコードように、検索結果の格納先をインライン宣言した場合、条件に合致する行データが存在しないと、例外 CX_SY_ITAB_LINE_NOT_FOUND が発生して処理が異常終了してしまう。
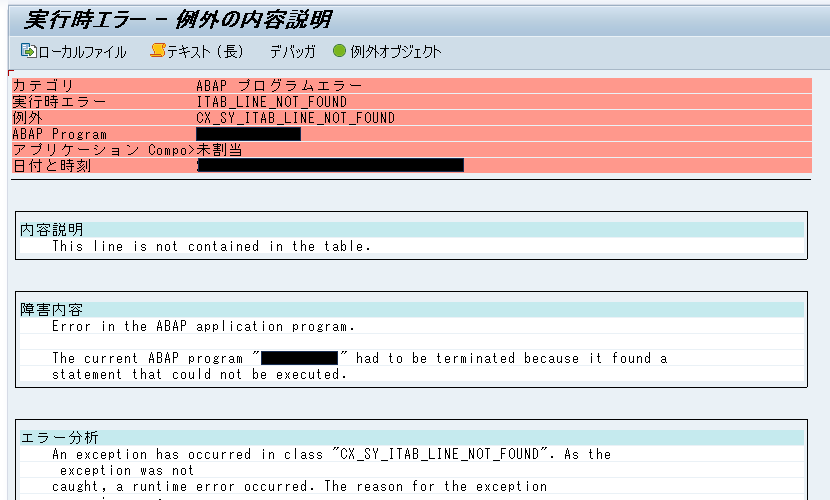
従って、検索失敗が想定される場合には、
- インライン宣言を行わずに、格納先の構造を事前に宣言しておく。
- CATCH ステートメントを使って例外を捕捉する。
等の対応を行い、例外の発生や異常終了を回避する必要がある。
なお、VALUE 演算子と OPTIONAL オプションを使って、例外の発生を抑制することも可能である。基本形は以下の通り。
VALUE 構造データ型( 内部テーブル名[ 検索条件 ] OPTIONAL ).
VALUE 演算子を使って構造に初期値を設定する記述方法を「VALUE 演算子」の項で学習したが、初期値の代わりに内部テーブル検索のコードを ( ) のなかに埋め込み、さらに最後に OPTIONAL を付け加える。
例えば、前述のコードを VALUE 演算子で書き換えると、以下のようになる。
DATA(profile) = VALUE zs_profile( profiles[
height = height
uninumber = uninum ] OPTIONAL ).内部テーブルの検索に失敗しても、各変数の初期値で構造 profile が生成されるので、例外 CX_SY_ITAB_LINE_NOT_FOUND が発生しない。
内部テーブル処理の組み込み関数
モダン ABAP では、内部テーブル処理のための組み込み関数が用意されている。
line_exists 関数
line_exists 関数と IF ステートメントを組み合わせて、検索条件に合致する行データの存在有無を確認できる。基本形は以下の通り。
IF line_exists( 内部テーブル名[ 検索条件 ] ).
行データが存在する場合に実行する処理
ENDIF.
IF の後に、半角スペースを挟んで line_exists と記述し、その後に、 (、半角スペース、内部テーブル名、[] で挟んで検索条件、半角スペースを挟んで )、の順に記述する。なお、IF ステートメントの後には、行データが存在する場合に実行する処理を記述する。
以下のコードは、検索条件に合致する行データの存在有無を line_exists 関数で確認し、存在する場合のみ内部テーブル検索と一覧画面表示を行うことで、例外による処理の異常終了を回避している。
IF line_exists( profiles[ height = height uninumber = uninum ] ).
DATA(profile) = profiles[ height = height uninumber = uninum ].
WRITE: profile-name, profile-height, profile-uninumber.
ENDIF.line_index 関数
line_index 関数を使って、検索条件に合致するデータの行番号を確認できる。基本形は以下の通り。
line_index( 内部テーブル名[ 検索条件 ] ).
line_index の後に、 (、半角スペース、内部テーブル名、[] で挟んで検索条件、半角スペースを挟んで )、の順に記述する。なお line_index の前に = を指定すると、事前定義 ABAP データ型 i で左辺に行番号が返る。
以下のコードは、line_index 関数を使って、検索条件に合致する行番号を確認し、 0 より大きい = 条件に合致する行データが存在する場合のみ、内部テーブル検索と一覧画面表示を行っている。
DATA(lineno) = line_index( profiles[ height = height uninumber = uninum ] ).
IF lineno > 0.
DATA(profile) = profiles[ height = height uninumber = uninum ].
WRITE: profile-name, profile-height, profile-uninumber.
ENDIF.なお、line_index 関数で確認した行番号を一時的に格納するために変数 lineno を使用しているが、処理の合間に一時的に使用する変数のことを ABAP では「ヘルパー変数(Helper Variable)」と呼んでいる。
モダン ABAP では、ヘルパー変数を使わない簡潔なコーディングが推奨されている。例えば、式指向のコーディングであれば、以下のように line_index 関数をそのまま IF ステートメントに組み込める。
IF line_index( profiles[ height = height uninumber = uninum ] ) > 0.
DATA(profile) = profiles[ height = height uninumber = uninum ].
WRITE: profile-name, profile-height, profile-uninumber.
ENDIF.FILTER 演算子を使った行抽出
FILTER は、内部テーブルから条件に合致する行データを抽出し、別の内部テーブルに行データをコピーする演算子である。FILTER 演算子は、二次キー(Secondary Key)が設定された標準テーブル(Standard Table)及び、ソートテーブル(Sorted Table)、ハッシュテーブル(Hashed Table)で使用できる。
二次キー付きの標準内部テーブルで FILTER 演算子を使用する際の基本形は以下の通り。
FILTER テーブルデータ型( コピー元の内部テーブル名 USING KEY 二次キー名 WHERE 検索条件 )
FILTER の後に半角スペースを挟んでコピー先のテーブルデータ型、(、半角スペースを前後に挟んでコピー元の内部テーブル名、USING KEY の後に半角スペースを前後に挟んで二次キー名、WHERE の後に半角スペースを挟んで検索条件、半角スペース、最後に ) 、の順に記述する。なお、検索条件には、二次キーに設定された変数を漏れなく指定する。
例えば、プロフィール内部テーブル profiles から身長 190 以上の選手のプロフィール情報を抽出して別の内部テーブルにコピーする。従来の ABAP であれば以下のようなコードになる。
DATA: profiles TYPE TABLE OF zs_profile
WITH NON-UNIQUE KEY key_height COMPONENTS height,
results TYPE TABLE OF zs_profile
WITH NON-UNIQUE KEY key_height COMPONENTS height,
profile TYPE zs_profile.
LOOP AT profiles INTO profile WHERE height >= 190.
APPEND profile TO results.
ENDLOOP.このコードを FILTER 演算子で書き換えると次のようになる。
DATA profiles TYPE TABLE OF zs_profile
WITH NON-UNIQUE KEY key_height COMPONENTS height.
....
DATA(results) = FILTER #( profiles USING KEY key_height WHERE height >= 190 ).内部テーブル profiles から変数 height が 190 以上の行データが抽出され、インライン宣言された内部テーブル results にコピーされる。なお、内部テーブル profiles のデータ型が明示的に指定されているので、FILTER の後のデータ型を # で省略できる。
なお、WHERE の前に EXCEPT オプションを追加すると、条件に合致する行が除外されて抽出される。
例えば、以下のコードの場合、変数 height の値が 190 未満の行データが抽出され、内部テーブル results にコピーされる。
DATA(results) = FILTER #( profiles USING KEY key_height
EXCEPT WHERE height >= 190 ).FOR 演算子と行コピー
FOR は、内部テーブルの行データを繰り返し読み込むための演算子である。VALUE や CORRESPONDING 等の演算子と組み合わせて使用する。
VALUE 演算子での使用
VALUE 演算子と組み合わせれば、別の内部テーブルに行データをコピーできる。基本形は以下の通り。
VALUE コピー先のテーブルデータ型( FOR 構造名 IN コピー元の内部テーブル名 ( コピー先の変数名 = 構造名-コピー元の変数名 .... ) )
VALUE 演算子の ( ) の中に FOR 演算子を組み込む。FOR の後に、半角スペース、行データを一時的に格納する構造名、半角スペースを前後に挟んで IN、その後にコピー元の内部テーブル名を記述する。構造は、指定した名前でインライン宣言されるので、事前に宣言しておく必要はない。
内部テーブル名の後には、半角スペースを挟んで ( ) を記述して、コピー元とコピー先の組み合わせを指定する。コピー先の内部テーブルの変数名、半角スペース、=、半角スペースの後、構造名、-(ハイフン)、コピー元の変数名、の順で組み合わせを指定し、半角スペースを挟んで組み合わせを複数指定できる。なお、( の後と ) の前には半角スペースを挟む。
VALUE の前に = を指定すると、左辺に指定した内部テーブルに行データがコピーされる。なお、コピー先の内部テーブルのデータ型が明示的に指定されている場合は、テーブルデータ型の指定を # で省略できる。
以下のコードは、選手のプロフィール情報を管理する zs_profile と、メンバー情報を管理する zs_member の2つの構造データ型を定義している。
* プロフィール構造データ型
TYPES: BEGIN OF zs_profile,
name TYPE ze_name,
birthday TYPE ze_birthday,
height TYPE ze_height,
weight TYPE ze_weight,
uninumber TYPE ze_uninumber,
END OF zs_profile.
* メンバー構造データ型
TYPES: BEGIN OF zs_member,
name TYPE ze_name,
uninumber TYPE ze_uninumber,
END OF zs_member.これらの構造データ型を使って、プロフィール情報を管理する内部テーブル profiles と、メンバー情報を管理する内部テーブル members を定義し、プロフィール情報が初期設定された内部テーブル profiles から変数 name(氏名)と uninumber(背番号)の値を内部テーブル members にコピーする処理を記述する。
従来の ABAP で記述すると、以下のようなコードになる。
DATA: profiles TYPE TABLE OF zs_profile,
profile TYPE zs_profile.
members TYPE TABLE OF zs_member,
member TYPE zs_member.
....
LOOP AT gdt_profile into gds_profile.
MOVE gds_profile-name TO gds_member-name.
MOVE gds_profile-uninumber TO gds_member-uninumber.
APPEND gds_member TO gdt_member.
ENDLOOP.FOR 演算子で書き換えると、以下のようになる。
DATA: profiles TYPE TABLE OF zs_profile,
members TYPE TABLE OF zs_member.
....
members = VALUE #( FOR profile IN profiles (
name = profile-name
uninumber = profile-uninumber ) ).式指向で複数の処理をまとめられるので、コードを簡潔に記述できる。また、内部テーブルの読み込みや編集で一時的に使う構造を予め用意しておく必要がない。
WHERE 句を使った条件検索
さらに、FOR 演算子の WHERE オプションで検索条件を指定すると、コピーする行データを絞り込める。基本形は以下の通り。
VALUE コピー先のテーブルデータ型( FOR 構造名 IN コピー元の内部テーブル名 WHERE ( 検索条件 ) ( .... ) )
コピー元の内部テーブル名を指定した後に、半角スペース、WHERE、半角スペース、( ) で囲んで検索条件を記述する。なお、( の後と ) の前には半角スペースを挟む。
以下のコードは、内部テーブル profiles から変数 uninumber の値が '18' の行データのみを抽出して、内部テーブル members にコピーしている。
members = VALUE #( FOR profile IN profiles
WHERE ( uninumber = '18' )
( name = profile-name
uninumber = profile-uninumber ).CORRESPONDING 演算子との組み合わせ
CORRESPONDING 演算子を組み合わせれば、コピー先とコピー元の組み合わせを指定しなくても、名前が同じ変数同士で自動的に値がコピーされる。基本形は以下の通り。
VALUE コピー先のテーブルデータ型( FOR 構造名 IN コピー元の内部テーブル名 ( CORRESPONDING コピー先のテーブルデータ型( 構造名 ) )
コピー元の内部テーブル名の後の ( ) の中に CORRESPONDING 演算子を組み込む。CORRESPONDING、コピー先テーブルデータ型、 ( ) の中には FOR の後に指定した同じ構造名を記述する。その際、( の後と ) の前には半角スペースを挟む。なお、コピー先の内部テーブルのデータ型が明示的に指定されている場合は、CORRESPONDING の後も # で省略できる。
例えば、以下のコードを
members = VALUE #( FOR profile IN profiles
( name = profile-name
uninumber = profile-uninumber ).CORRESPONDING 演算子で以下のように書き換えられる。
members = VALUE #( FOR profile IN profiles ( CORRESPONDING #( profile ) ) ).= 演算子を使った行コピー
なお、同じデータ型の内部テーブルにデータをそのままコピーするのであれば、= 演算子のみを使って簡潔にコードを記述できる。基本形は以下の通り。
コピー先の内部テーブル名 = コピー元の内部テーブル名.
以下のコードは、プロフィール内部テーブル profiles と同じデータ型の内部テーブル members をインライン宣言で生成して、profiles の行データをそのままコピーしている。
DATA(members) = profiles.REDUCE 演算子を使った集計処理
REDUCE は、内部テーブルの行データを集計するための演算子である。FOR 演算子を組み込んで使用する。
FOR 演算子の組み込み
FOR 演算子を組み込んで集計処理を行う際の基本形は以下の通り。
REDUCE 集計結果のデータ型( INIT 集計結果を格納する変数名 = 初期値 FOR 構造名 IN 処理対象の内部テーブル名 NEXT 集計処理 )
まず、REDUCE の後に半角スペースを挟んで集計結果のデータ型、(、半角スペースを前後に挟んで INIT、集計結果を一時保存する変数名、半角スペースを全前後に挟んで =、集計処理を始める時点の初期値を、順番に記述する。初期値を指定した後は、半角スペースを挟んで FOR 演算子の式を組み込み、半角スペースを前後に挟んで集計処理の計算式、半角スペースの後、) を記述する。なお、REDUCE の前に = を指定すれば、最終的な集計結果が左辺に指定した変数に指定したデータ型で代入される。
例えば、プロフィール内部テーブル profiles の全行の変数 height(身長)の値を集計して一覧画面に表示する場合、従来のコーディングで記述すると以下のようになる。
DATA: profiles TYPE TABLE OF zs_profile,
profile TYPE zs_profile,
total TYPE i.
....
MOVE 0 TO total.
LOOP AT profiles INTO profile.
ADD profile-height TO total.
ENDLOOP.
WRITE: '身長合計', total.このコードを REDUCE 演算子で書き替えると以下のようになる。
DATA profiles TYPE TABLE OF zs_profile.
....
DATA(total) = REDUCE i( INIT height = 0
FOR profile IN profiles
NEXT height = height + profile-height ).
WRITE: '身長合計', ldf_total.まず、従来のコーディングと異なり、行データを読み込む構造と、身長の集計値を格納する変数を予め宣言する必要がない。
続いて、集計結果を格納する変数の初期化と LOOP 処理を REDUCE 演算子の式で置き換えている。INIT の後に集計結果を一時的に格納する変数 height をインライン宣言して、初期値 0 を設定している。なお、REDUCE 演算子の後に集計結果のデータ型 i を指定しているので、変数 height のデータ型も i になる。
INIT ブロックの後には、インライン宣言した構造 profile に内部テーブル profiles の行データを FOR 演算子を使って読み込んでいる。
NEXT ブロックでは、読み込んだ行データごとに行う計算式を記述する。この例では、INIT ブロックで宣言した変数 height に構造 profile の変数 height の値を加算している。
なお、すべての行データの加算処理が終了すると、REDUCE 演算子の左辺にインライン宣言された変数 total に身長の集計結果がデータ型 i で代入される。
WHERE 句を使った集計の絞り込み
FOR 演算子の WHERE オプションで検索条件を指定すると、集計する行データを絞り込める。
以下のコードは、内部テーブル gdt_profile にある身長 190 以上の行データの件数を数えて一覧画面に表示している。
DATA gdt_profile TYPE TABLE OF zs_profile.
....
DATA(ldf_counter) = REDUCE i( INIT ldf_value = 0
FOR lds_profile IN gdt_profile
WHERE ( height >= 190 )
NEXT ldf_value = ldf_value + 1 ).
WRITE: '身長 190 以上のプロフィール件数', ldf_counter.構造を使った集計
戻り値のデータ型を構造にすると、複数の集計処理を同時に行って構造の各変数に結果を格納して左辺に返すことができる。基本形は以下の通り。
REDUCE 構造データ型( INIT 集計結果を格納する構造 = VALUE 構造データ型( 各変数の初期値設定 ) FOR 構造名 IN 処理対象の内部テーブル名 NEXT 変数ごとの集計処理 .... )
INIT の後に集計結果を一時的に格納する構造名を指定し、= の後に VALUE 演算子を使って構造の各変数の初期値を指定する。なお、NEXT の後には、集計処理の計算式を半角スペースを挟んで複数指定できる。
以下のコードでは、REDUCE 演算子を使って、内部テーブル profiles の身長と体重の値を同時に集計している。データ型に zs_result を指定して、インライン宣言した構造 result の変数 height と weight に身長と体重の集計値を返している。
TYPES: BEGIN OF zs_result,
height TYPE zacae_height_001,
weight TYPE zacae_weight_001,
END OF zs_result.
....
DATA profiles TYPE TABLE OF zs_profile.
....
DATA(result) = REDUCE zs_result(
INIT amount = VALUE zs_result( height = 0 weight = 0 )
FOR profile IN profiles
NEXT amount-height = amount-height + profile-height
amount-weight = anmont-weight + profile-weight ).
WRITE: '身長合計', ldf_result-height, '体重合計', ldf_result-weight.まず、INIT ブロックでは、集計結果を一時的に格納する構造 amount をインライン宣言して、VALUE 演算子を使って、構造 amount の変数 height と weight に初期値 0 を設定している。
続いて、FOR 演算子を使って、インライン宣言した構造 profile に内部テーブル profiles の行データを読み込んでいる。
NEXT ブロックでは、身長を集計して構造 amount の変数 height に代入する計算式と、体重を集計して構造 amount の変数 weight に代入する計算式を記述している。
なお、VALUE 演算子で構造データ型を指定しているので、以下のように REDUCE 演算子の後は # で省略できる。
DATA(result) = REDUCE #(
INIT amount = VALUE zs_result( height = 0 weight = 0 )
FOR profile IN profiles
NEXT amount-height = amount-height + profile-height
amount-weight = amount-weight + profile-weight ).