モダン ABAP の文字列処理
ABAP プログラミングでは、事前定義 ABAP データ型の c や string、ABAP ディクショナリデータ型 の CHAR や STRING を使って文字列を処理する。
c や CHAR は、固定長の領域に文字列を格納する。変数宣言やドメインで定義した長さ(文字数)で文字列が処理される。以下のコードでは、文字列変数 text をデータ型 c、長さ 5 で定義して、最初に 4 文字の文字列、次に 6 文字の文字列を代入している。
DATA text TYPE c LENGTH 5 VALUE space.
....
text = 'abcd'. "4 文字代入
WRITE text.
text = 'abcdef'. "6 文字代入
WRITE: / text.実行結果は、以下のようになる。

文字長 5 の変数 text に対して、最初に代入した文字列 'abcd' は 4 文字なので、文字列全体が正しく一覧画面に表示されるが、次に代入した文字列 'abcdef' は 6 文字なので、最後の文字 f が欠けた状態で表示される。
一方、string や STRING は、可変長の領域に文字列を格納する。代入された文字列に応じて領域の大きさが調整される。例えば、変数 text をデータ型 string に変更すると、
DATA text TYPE string VALUE space.実行結果は、以下のようになる。

代入された文字列に合わせて変数 text の領域が可変するので、文字列 'abcdef' が正しく表示される。
多くの SAP 標準アプリケーションでは、文字列データを固定長で管理しているので、 データ型 c や CHAR を使った文字列処理が一般的であった。しかし、モダン ABAP では、一般的なプログラミング言語のように、文字列を可変長で処理することを想定して機能拡張が行われている。
モダン ABAP では、代入する文字列を`(バッククォート)で囲んで指定すると、データ型 string の文字列変数が自動生成される。前述のコードを変更して、文字列を代入する変数 text をインライン宣言する。代入する文字列を従来の '(シングルクォート)で囲んで記述すると、
DATA(text) = 'abcd'. "シングルクォートで 4 文字代入
WRITE text.
text = 'abcdef'. "6 文字代入
WRITE: / text.実行結果は、以下のようになる。
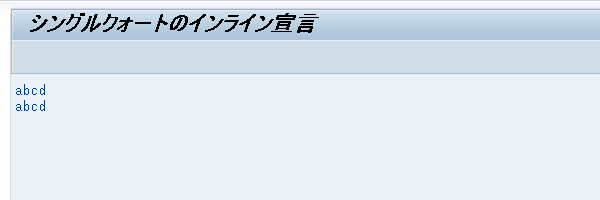
インライン宣言した変数 text は、最初の文字列 'abcd' に合わせて長さ 4 のデータ型 c で生成されるので、次に代入した文字列 'abcdef' の 5 文字目以降が欠けてしまう。
続いて、インライン宣言の文字列を `(バッククォート)で書き換えると、
DATA(text) = `abcd`. "バッククォートで 4 文字代入
....実行結果は、以下のようになる。
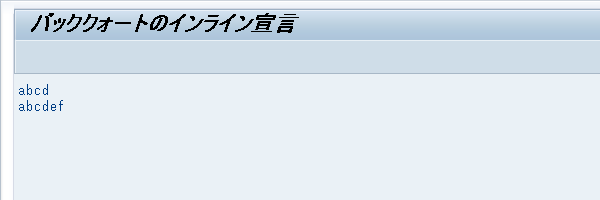
文字列 `abcd` がバッククォートで囲まれているので、インライン宣言の変数 text はデータ型 string で生成される。従って、次に代入した文字列 'abcdef' も正しく表示される。
なお、インライン宣言以外でも、モダン ABAP で文字列を記述する際には、固定長には ' (シングルクォート)、可変長には `(バッククォート)を使い分けることが推奨されている。
文字列関数とは
モダン ABAP では、文字列を処理するための関数が追加されている。なお、関数(Function)とは、Returning パラメーターを持つクラスのメソッドのように、処理結果を = の左辺に返す組み込み機能で、式指向コーディングで演算子と組み合わせて使用できる。
従来の ABAP コーディングでは、REPLACE や TRANSLATE、CONDENSE 等のステートメントを使って文字列を処理していた。しかし、式指向のコーディングができないので、モダン ABAP では文字列を処理するための関数が提供されている。
関数は、関数名の後に ( ) を記述し、( ) のなかに関数に引き渡す値を指定する。また、関数で処理された結果は、関数名の前に記述した = の左辺に引き渡される。
主な文字列関数は、以下の通り。
| 関数名 | 機能 | 代替元のステートメント |
|---|---|---|
| replace | 文字列置換 | REPLACE |
| to_lower | 小文字変換 | TRANSLATE .... TO LOWER CASE |
| to_upper | 大文字変換 | TRANSLATE .... TO UPPER CASE |
| condense | 半角スペース除去 | CONDENSE |
| count | 文字列カウント | |
| find | 文字列位置取得 | |
| contains | 文字列存在確認 | |
| strlen | 文字数カウント | |
| substring | 文字列切り出し |
replace 関数を使った文字列置換
replace は、文字列を置き換えるための関数で、従来の REPLACE ステートメントを代替する。replace 関数の基本形は以下の通り。
replace( val = 処理対象の文字列 sub = 置換前の文字列 with = 置換後の文字列 )
関数名の replace の直後に (、半角スペース、処理対象の文字列を引き渡すためのパラメーター名 val、前後に半角スペースを挟んで = を記述し、処理対象の文字列や変数名を指定する。
次に、半角スペースを挟んで、処理対象の文字列に含まれる置き換え前の文字列を指定するパラメーター名 sub、前後に半角スペースを挟んで =、その後に置換前の文字列を指定する。
続いて、半角スペースを挟んで、置換後の文字列を指定するパラメーター名 with、前後に半角スペースを挟んで =、その後に置き換え後の文字列を指定し、最後に半角スペースを挟んで ) を記述する。
なお、replace の前に = を指定すると、左辺に文字列置換の結果が返される。また、パラメーターに引き渡す文字列を変数で指定できる。
以下のコードは、REPLACE ステートメントを使って、事前定義 ABAP データ型 c の変数 text に格納された文字列 'abZZZfg' の 'ZZZ' の部分を 'cde' に置き換えて 'abcdefg' にする処理を記述している。
DATA text TYPE c LENGTH 7 VALUE 'abZZZfg'.
....
REPLACE 'ZZZ' IN text WITH 'cde'.このコードを replace 関数で書き換えると、以下のようになる。
text = replace( val = text sub = 'ZZZ' with = 'cde' ).REPLACE の後に記述した置換前の文字列を sub パラメーター、IN 句で指定した処理対象の変数を val パラメーター、WITH 句で指定した置換後の文字列を with パラメーターで指定している。また、REPLACE ステートメントと同様に、文字列置換の結果を元の変数に上書きするため、左辺に処理対象の変数 text を指定している。
なお、replace 関数を使えば、処理対象の変数を上書きせずに、置換後の文字列を別の変数に代入できる。以下のコードは、置換後の文字列をインライン宣言した変数 result に代入している。
DATA(result) = replace( val = text sub = 'ZZZ' with = 'cde' ).to_lower と to_upper 関数を使った文字列変換
to_lower は、アルファベットの文字列を小文字に変換し、to_upper は大文字に変換する関数で、従来の TRANSLATE ステートメントを代替する。to_lower、to_upper 関数の基本形は以下の通り。
to_lower( val = 処理対象の文字列 ) または、 to_lower( 処理対象の文字列 )
to_upper( val = 処理対象の文字列 ) または、 to_upper( 処理対象の文字列 )
関数名の直後に (、半角スペース、処理対象の文字列を引き渡すためのパラメーター名 val、前後に半角スペースを挟んで =、処理対象の文字列を指定して、最後に半角スペースを挟んで ) を記述する。なお、( ) で指定するパラメーターが1つなので val = の記述を省略できる。また、パラメーターに引き渡す文字列を変数で指定できる。関数名の前に = を指定すると、左辺に文字列変換の結果が返される。
以下の TRANSLATE ステートメントのコードを、
TRANSLATE text1 TO LOWER CASE.
TRANSLATE text2 TO UPPER CASE.to_lower、to_upper 関数で書き換えると、以下のようになる。
text1 = to_lower( text1 ).
text2 = to_upper( text2 ).TRANSLATE の後に記述した処理対象の変数名を ( ) の中に指定し、変換後の文字列を代入する変数を = の左辺に指定する。なお、変換元の変数の値を上書きしない場合は、左辺に別の文字列変数を指定する。
condense 関数を使った半角スペース除去
condense は、文字列の前後の半角スペースを削除し、文字列中の連続する半角スペースを1文字分のスペースに圧縮する関数で、従来の CONDENSE ステートメントを代替する。condense 関数の基本形は以下の通り。
condense( val = 処理対象の文字列 ) または、 condense( 処理対象の文字列 )
関数名 condense の直後に (、半角スペース、処理対象の文字列を引き渡すためのパラメーター名 val、前後に半角スペースを挟んで =、処理対象の文字列や変数名を指定して、最後に半角スペースを挟んで ) を記述する。なお、この記述方法の場合は、val = の記述を省略できる。また、パラメーターに引き渡す文字列を変数で指定できる。condense の前に = を指定すると、左辺に半角スペースが除去された文字列が返される。
以下の CONDENSE ステートメントを、
CONDENSE text.condense 関数で書き換えると、以下のようになる。
text = condense( text ).CONDENSE の後に記述した処理対象の変数名を ( ) の中に指定し、変換後の文字列を代入する変数を = の左辺に指定する。なお、変換元の変数の値を上書きしない場合は、左辺に別の文字列変数を指定する。
CONDENSE ステートメントで NO-GAPS 句を追加すると、文字列のすべての半角スぺースが除去される。以下のコードでは、変数 text の文字列が ' AB C ' から 'ABC' に変換される。
DATA text TYPE c LENGTH 8 VALUES ' AB C '.
....
CONDENSE text NO-GAPS.condense 関数で行う場合の基本形は以下の通り。
condense( val = 処理対象の文字列 from = ` ` to = `` )
( ) の中で、val パラメーターで処理対象の文字列を指定した後で、半角スペースを挟んで from、前後に半角スペースを挟んで =、その後に `(バッククォート)、半角スペース、`(バッククォート) を記述する。
続いて、半角スペースを挟んで to、前後に半角スペースを挟んで =、その後に ``(バッククォートを2つ連続)、最後に半角スペースを挟んで ) を記述する。
上記の CONDENSE .... NO GAPS ステートメントを書き換えると、以下のようになる。
text = condense( val = text from = ` ` to = `` ). 関数を使った文字列確認
モダン ABAP では、文字列を確認するための関数が新たに用意されている。
count 関数
count は、指定した文字や文字列が、確認対象の文字列の中に含まれる数を確認する関数である。基本形は以下の通り。
count( val = 確認対象の文字列 sub = 指定の文字や文字列 )
関数名 count の直後に (、半角スペース、確認対象の文字列を引き渡すためのパラメーター名 val、前後に半角スペースを挟んで =、処理対象の文字列や変数名を指定する。
続いて、半角スペースを挟んで特定文字列を指定するパラメーター名 sub、前後に半角スペースを挟んで =、指定の文字や文字列、半角スペースを挟んで、最後に ) を記述する。
パラメーターで引き渡す文字列は変数で指定できる。なお、count の前に = を指定すると、確認結果が整数値で左辺に返される。
以下のコードは、文字列 'ABAP' の中に含まれる 'A' の数を確認している。
DATA(counter) = count( val = 'ABAP' sub = 'A' ).val パラメーターに確認対象の文字列 'ABAP' を、sub パラメーターには 'A' を指定しています。コードを実行すると、左辺にインライン宣言した変数 counter に 2 が代入される。
次のコードは、count 関数を使って住所の判定を行っている。変数 address に更新された住所情報に「港区」の文字列が 1 つ以上含まれている = count 関数の戻り値が 0 より大きい場合は、一覧画面に「これは、港区の住所です。」を表示している。
DATA: address TYPE c LENGTH 100 VALUE space,
....
DATA(counter) = count( val = address sub = '港区' ).
IF counter > 0.
WRITE: / 'これは、港区の住所です。'.
ENDIF.なお、count 関数は式指向でコードできるので、以下のように簡潔に記述できる。
IF count( val = address sub = '港区' ) > 0.
WRITE: / 'これは、港区の住所です。'.
ENDIF.find 関数
find は、指定した文字や文字列が確認対象の文字列の何文字目に含まれているのかを確認する関数である。基本形は以下の通り。
find( val = 確認対象の文字列 sub = 指定の文字や文字列 )
記述方法は、count 関数と同様で、find の前に = を指定すると、確認結果が整数値で左辺に返される。確認対象の文字列の1文字目にある場合は 0、2文字目は 1 、3文字目は 2、、、、のように 文字位置から 1 を引いた値が返される。なお、指定の文字列が存在しない場合は、-1 が返される。
以下のコードは、文字列 'ABAP' の中にある 'A' と 'Z' の位置を確認している。
DATA(position1) = find( val = 'ABAP' sub = 'A' ).
DATA(position2) = find( val = 'ABAP' sub = 'Z' ).文字列 'ABAP' の中には複数の 'A' が存在するので、最初の 'A' の位置が左辺に返される。最初の 'A' は 1 文字目なので、変数 position1 には 0 が代入される。
また、文字列 'ABAP' には 'Z' が含まれていないので、変数 position2 には -1 が代入される。
次のコードは、count 関数を使った住所判定のコードを find 関数で書き換えてる。変数 address に更新された住所情報に「港区」の文字列が含まれている = count 関数の戻り値が -1 より大きい場合に、「これは、港区の住所です。」を一覧画面に表示する。
IF find( val = address sub = '港区' ) > -1.
WRITE: / 'これは、港区の住所です。'.
ENDIF.contains 関数
contains は、指定した文字や文字列が確認対象の文字列に含まれていれば true(真)、含まれていなければ false(偽)を返す関数である。基本形は以下の通り。
contains( val = 確認対象の文字列 sub = 指定の文字や文字列 )
記述方法は、count や find 関数と同様だが、= 演算子を使わずに、条件判断の式に組み込んで使用する。
以下のコードは、前述の住所判定の処理を contains 関数で書き換えている。contains 関数単体で条件式を構成できるので、count や find 関数のように戻り値を判断するコードを省略できる。
IF contains( val = address sub = '港区' ).
WRITE: / 'これは、港区の住所です。'.
ENDIF.strlen 関数
strlen は、文字列の長さ(文字数)を確認する関数である。基本形は以下の通り。
strlen( 処理対象の文字列 )
関数名 strlen の直後に (、半角スペース、文字数を確認する文字列を指定し、最後に半角スペースを挟んで ) を記述する。文字列は変数で指定できます。
strlen の前に = を指定すると、文字数果が整数値で左辺に返される。なお、文字列の先頭や、文字列の間に半角スペースがある場合は、半角スペースも文字として識別される。
以下のコードは、文字列 ’abcdef' を '(シングルクォート)で囲って指定し、 strlen 関数を使って文字数を確認している。
data(counter) = strlen( 'abcdef' ).変数 counter には 6 が代入される。
次のコードは、a の前と、各文字の間、f の後に半角スペースを挟んだ文字列 ' a b c d e f ' の文字数を確認している。
data(counter) = strlen( ' a b c d e f ' ).6 文字のアルファベットと、a の前と文字の間に挟まれた 6 つの半角スペースを合わせた 12 が変数 counter に代入される。
なお、string 型の文字列の場合は、文字列の最後にある半角スペースも文字として識別される。
前述のコードと同じ文字列を `(バッククォート)で囲って文字数を確認すると、
data(counter) = strlen( ` a b c d e f ` ).f の後にある半角スペースもカウントされるので、変数 counter には 13 が代入される。
substring 関数を使った文字列抽出
substring は、文字列の一部を抽出する関数である。基本形は以下の通り。
substring( val = 抽出元の文字列 off = 抽出の開始位置 len = 抽出する文字数 )
関数名 substring の直後に (、半角スペース、抽出元の文字列を引き渡すためのパラメーター名 val、前後に半角スペースを挟んで =、抽出元の文字列や変数名を指定する。
次に、半角スペースを挟んで、抽出する文字列の開始位置(オフセット)を指定するパラメーター名 off、前後に半角スペースを挟んで =、抽出を開始する文字位置を整数値で指定する。なお、文字位置は、1 文字目であれば 0、2 文字目では 1 、3 文字目は 2、、、のように 1 を引いた値で指定する。
続いて、半角スペースを挟んで、抽出する文字列の長さ(文字数)を指定するパラメーター名 len、前後の最後に半角スペースを挟んで =、抽出する文字数を整数値で指定し、半角スペースを挟んで、最後に ) を記述する。
substring の前に = を指定すると、抽出された文字列が左辺に返される。なお、抽出元の文字列を '(シングルクォート)で囲んだ場合でも、戻り値の文字列は string 型になる。
以下のコードは、文字列 `abcdef` の 2 文字目から 3 文字分の文字列 `bcd` が抽出され、左辺の変数 text に代入される。
data(text) = substring( val = `abcdef` off = 1 len = 3 ).文字列確認の関数を組み合わせることで、より複雑な条件で文字列を抽出できる。次のコードは、変数 address に港区の住所が格納されていた場合に、港区の後に続く町名や番地の文字列を抽出して変数 street に代入している。
IF contains( val = address sub = '港区' ).
....
data(off) = find( val = address sub = '港区' ) + 2.
data(len) = strlen( address ) - off.
DATA(street) = substring( val = address off = off len = len ).
WRITE: / '町名以降の住所は、', street, 'です。'.
ENDIF.まず、contains 関数を使って、変数 address に格納された住所に「港区」の文字列が含まれていることを確認している。
次に、find 関数を使って、文字列「港区」の開始位置を確認し、開始位置から「港区」の 2 文字分を加算した位置 = 町名の開始位置を変数 off に代入している。
続いて、strlen 関数を使って、変数 address に格納された住所全体の文字数を取得し、住所全体の文字数から町名の開始位置を減算した数 = 町名以降の文字数を変数 len に代入している。
そして、町名の開始位置が代入された変数 off を off パラメーターに、町名以降の文字数が代入された変数 len を len パラメーターに指定して substring 関数で文字列を抽出し、港区の後に続く町名や番地を変数 street に代入している。
&& 演算子を使った文字列結合
&& は、文字列を結合するための演算子で、従来の CONCATENATE ステートメントを代替する。基本形は以下の通り。
1 つ目の文字列1 && 2 つ目の文字列 ....
結合したい文字列の間に && を記述する。&& の前後には半角スペースを挟む。なお、文字列を変数で指定できる。1つ目の文字列の前に = を指定すると、左辺に結合された文字列が返る。
以下のコードは、CONCATENATE ステートメントでデータ型 c の変数に格納された文字列を結合している。
DATA: address TYPE c LENGTH 100 VALUE space,
prefecture TYPE c LENGTH 20 VALUE '東京都',
city TYPE c LENGTH 20 VALUE '港区',
street TYPE c LENGTH 20 VALUE '三田',
street_no TYPE c LENGTH 20 VALUE '1-4-28'.
....
CONCATENATE prerecture city street street_no INTO address.このコードを実行すると、変数 address には、文字列 '東京都港区三田1-4-28' が代入される。
このコードを && 演算子で書き換えると、以下のようになる。
address = prefecture && city && street && street_no.CONCATENATE ステートメントと同様に、結合する文字列の後に含まれる半角スペースは無視されるので、文字列 '東京都港区三田1-4-28' が変数 address に代入される。
なお、左辺の変数をインライン宣言すると、結合する文字列のデータ型に関係なく、string 型で変数が生成される。以下のコードでは、結合する 4 つの変数ともにデータ型が c だが、
DATA: address TYPE c LENGTH 100 VALUE space,
prefecture TYPE c LENGTH 20 VALUE '東京都',
city TYPE c LENGTH 20 VALUE '港区',
street TYPE c LENGTH 20 VALUE '三田',
street_no TYPE c LENGTH 20 VALUE '1-4-28'.
....
DATA(address) = prefecture && city && street && street_no.インライン宣言で生成される変数 address のデータ型は string になる。
また、結合する文字列が string 型で、文字列の後に半角スペースが挿入されている場合は、半角スペースも含めて文字列が結合される。例えば、以下のコードを実行すると、
DATA: prefecture TYPE string VALUE `東京都 `,
city TYPE string VALUE `港区 `,
street TYPE string VALUE `三田 `,
street_no TYPE string VALUE `1-4-28 `.
....
DATA(address) = prefecture && city && street && street_no.変数 address には、文字列 `東京都 港区 三田 1-4-28 `が代入される。
文字列テンプレート
文字列テンプレート(String Template)機能を使うと、変数の値や式の実行結果を組み込んで文字列を簡易に編集できる。
文字列テンプレートは、文字列の前後に|(パイプ)を挟み、埋め込む変数や式を{ } (波括弧)で囲んで作成する。なお、{ と後と } の前には半角スペースを挟む。テンプレートで生成された文字列は、= 演算子を使って左辺の変数に代入される。なお、変数をインライン宣言した場合は、string 型の変数が自動生成される。
変数の組み込み
以下のコードは、データ型 c の変数 name を組み込んだ文字列テンプレートを定義し、編集した文字列を変数 text に代入している。
DATA name TYPE c LENGTH 20 value '広沢克己'.
....
DATA(text) = |名前は、{ name }です。|.このコードを実行すると、string 型の変数 text が生成され、文字列「名前は、広沢克己です。」が代入される。なお、変数 name の長さは 20 だが、値の後の不要な半角スペースは除去されて文字列に埋め込まれる。
文字列テンプレートは、複数の変数を組み込んで文字列を結合できる。以下のコードは、文字列テンプレートを使って、4 つの変数に格納された文字列を1つにまとめている。
DATA: prefecture TYPE c LENGTH 20 VALUE '東京都',
city TYPE c LENGTH 20 VALUE '港区',
street TYPE c LENGTH 20 VALUE '三田',
street_no TYPE c LENGTH 20 VALUE '1-4-28'.
....
DATA(address) = |{ prefecture }{ city }{ street }{ street_no }|.変数 adress には、文字列「東京都港区三田1-4-28」が代入される。
以下のコードは、データ型 i の変数 height の値を文字列に埋め込む処理をしている。
DATA: name TYPE c LENGTH 20 value '池山隆寛',
height TYPE i value 183,
height_s TYPE string,
text TYPE string.
....
MOVE height TO height_s. "代入で数値を文字列に変換
CONCATENATE '名前は、' name 'で、身長は、' height_s 'です。' INTO text.このように、従来の ABAP では、文字変数に数値を代入して文字列に変換してから、文字列結合で値を埋め込む必要があった。これを文字列テンプレートで書き直すと、以下のようになる。
DATA(text) = |名前は、{ name }で、身長は、{ height }です。|.テンプレートの中に数値の変数を指定すると、自動的に数値が文字列に変換される。変数 text には、文字列「名前は、池山隆寛平で、身長は、183です。」が代入される。
式の組み込み
文字列テンプレートに式を組み込んで、実行結果を文字列に埋め込める。
例えば、四角形の面積を計算して覧画面に表示する。従来の ABAP では、以下のように計算結果を変数に格納してから文字列を編集する必要があった。
DATA: area TYPE i,
area_s TYPE string,
text TYPE string.
....
PARAMETERS: base TYPE i OBLIGATORY,
height TYPE i OBLIGATORY.
....
area = base * height.
MOVE area TO area_s.
CONCATENATE '面積は、' area_s 'です。'
INTO text.
WRITE text.文字列テンプレートを使えば、面積の計算と計算結果の文字列変換、そして一覧画面に表示する文章の編集までの処理を以下のように書き換えられる。
DATA(text) = |面積は、{ base * height } です。|.面積の計算式を { } で囲んで文字列テンプレートに組み込むと、計算結果が前後の文字列と結合されて、インライン宣言された変数 text に代入される。
大小文字変換
CASE オプションを使うと、大文字または小文字に変換して文字列を挿入できる。基本形は以下の通り。
{ 変数名 CASE = UPPER または LOWER または RAW }
{、半角スペース、変数名の後に、前後に半角スペースを挟んで =、その後に、大文字に変換する場合は UPPER、小文字に変換する場合は LOWER、変換しない場合は RAW を指定し、半角スペースを挟んで } で閉じる。なお、変数名の代わりに文字列を指定する場合は、'(シングルクォート)または `(バッククォート)で囲んで記述する。
以下のコードは、文字列 `Hello World` が格納された変数 greeting を CASE オプションを使って変換している。変数 text1 には `HELLO WORLD`、変数 text2 には `hello world`が代入される。また、変数 text3 には、元の文字列 `Hello World` がそのまま代入される。
DATA greeting TYPE string VALUE `Hello World`.
....
DATA(text1) = |{ greeting CASE = UPPER }|.
DATA(text2) = |{ greeting CASE = LOWER }|.
DATA(text3) = |{ greeting CASE = RAW }|.文字列の長さと詰め方向
LENGTH オプションを使って、変換後の文字列の長さを指定できる。さらに、ALIGN オプションを追加すると、文字詰めの方向を指定できる。基本形は以下の通り。
{ 変数名 LENGTH = 文字数 ALIGN = RIGHT または LEFT }
LENGTH の後には文字数、ALIGN の後には、RIGHT(右詰め)または LEFT(左詰め)を指定する。
以下のコードは、変数 greeting の文字列 `Hello World` を 20 文字の長さに変換している。ALIGN オプションが指定されているので、変数 text1 には右詰めで ` Hello World` が、変数 text2 には左詰めで `Hello World `が代入される。
DATA greeting TYPE string VALUE `Hello World`.
....
DATA(text1) = |{ greeting LENGTH = 20 ALIGN = RIGHT }|.
DATA(text2) = |{ greeting LENGTH = 20 ALIGN = LEFT }|.日付、時刻、数値の文字列変換
日付や時刻、数値を文字列に変換するためのオプションも用意されている。例えば、日付、時刻、数値の変数をそのまま文字列テンプレートに埋め込むと、
DATA so_header TYPE vbak.
....
DATA(text1) = |登録日付は、{ so_header-erdat } です。|.
WRITE / text1.
DATA(text2) = |登録時刻は、{ so_header-erzet } です。|.
WRITE / text2.
DATA(text3) = |販売金額は、{ so_header-netwr } { so_header-waerk } です。|.
WRITE / text3.
DATA(text4) = |伝票番号は、{ so_header-vbeln } です。|.
WRITE / text4.実行結果は、以下のようになる。
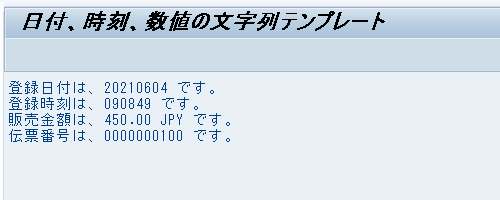
DATE(日付)、TIME(時刻)、NUMBER(数値)オプションを使用すると、ユーザープロファイルのデフォルト設定に合わせて文字列が編集される。基本形は以下の通り。
{ 変数名 DATE = USER }
{ 変数名 TIME = USER }
{ 変数名 NUMBER = USER }
これらのオプションを前述のコードに追加すると、
DATA so_header TYPE vbak.
....
DATA(text1) = |登録日付は、{ so_header-erdat DATE = USER } です。|.
WRITE / text1.
DATA(text2) = |登録時刻は、{ so_header-erzet TIME = USER } です。|.
WRITE / text2.
DATA(text3) = |販売金額は、{ so_header-netwr NUMBER = USER } { so_header-waerk } です。|.
WRITE / text3.
DATA(text4) = |伝票番号は、{ so_header-vbeln } です。|.
WRITE / text4.実行結果は、以下のようになる。
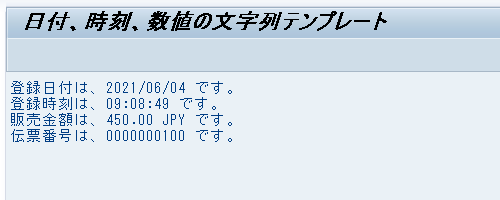
ユーザーのデフォルト設定に合わせて、登録日付は YYYY/MM/DD 形式、登録時刻は HH:MM:SS 形式で表示され、販売金額は、3 桁区切りが ,(カンマ)、小数点は .(ピリオド)で表示されている。
金額補正
SAP システムでは、小数 2 桁のデータベース項目で金額データが保持されるため、JPY(日本円)を含む一部の通貨の金額データは、画面等に出力する際に小数点の位置を補正する必要がある。文字列テンプレートの CURRENCY オプションを使えば、通貨コードに応じて小数点を自動補正してくれる。基本形は以下の通り。
{ 金額の変数名 CURRENCY = 通貨コードの変数名 }
金額データの変数名の後に、オプション CURRENCY 、= の後には、通貨コードが格納された変数名を指定する。
前述した販売金額の文字列テンプレートに CURRENCY オプションを追加すると、
DATA(text3) = |販売金額は、{ so_header-netwr NUMBER = USER CURRENCY = so_header-waerk } { so_header-waerk } です。|.実行結果は、以下のようになる。
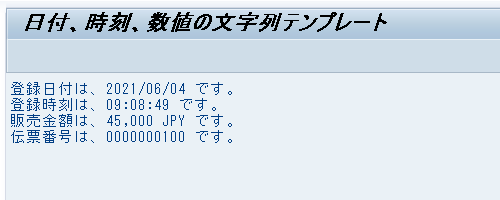
小数点位置が補正されて、販売金額の 45,000 円が正しく一覧画面に表示されている。
数字文字列のゼロ詰め
ALPHA は、数字文字列の先頭にある 0 を編集するオプションで、ドメインの変換ルーチン ALPHA と同様の処理を行える。基本形は以下の通り。
{ 変数名 ALPHA = OUT または IN }
金額データの変数名の後に、オプション ALPHA 、= の後には、文字列の先頭を 0 詰めする(= 内部値にする)場合は IN、先頭の 0 を取り除く(=外部値にする)場合は OUT を指定する。
以下のコードは、販売伝票番号の文字列テンプレートに ALPHA オプションを追加して先頭の 0 を除去している。
DATA(text4) = |伝票番号は、{ so_header-vbeln ALPHA = OUT } です。|.実行結果は、以下のようになる。

伝票番号 '0000000100' の先頭の 0 が取り除かれて '100' で表示されている。
その他のオプション
文字列テンプレートには、他にも様々なオプションが用意されている。詳細については、SAP 社のオンラインヘルプに記載されている。